开云app下载 DeepSeek新论文剧透V4新框架! 用闲置网卡加快智能体推感性能

henry 发自 凹非寺
DeepSeek这小子最精了,当全全国王人在盯着他的GitHub仓库,恭候V4时——
他和北大、清华在ArXiv悄咪咪地上了一篇论文,发布了一个全新的针对智能体的推理框架:DualPath。

况且就跟前几天曝出的算力话题联系。
DualPath的中枢在于料理Agent长文本推理场景下的I/O瓶颈,通过优化从外部存储加载KV-Cache的速率,确保策划资源不被存储读取攀扯。
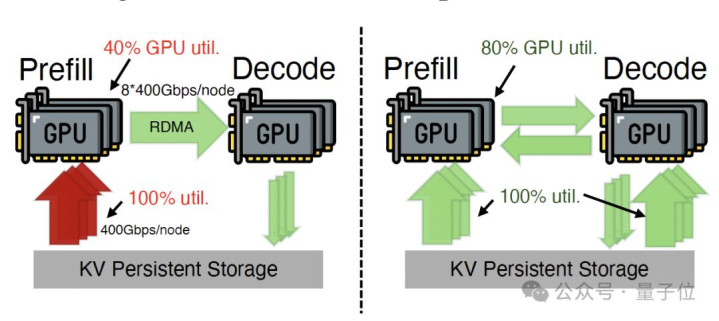
它改动了传统的存储至预填充引擎(Storage-to-Prefill)单旅途加载现象,引入了存储至解码引擎(Storage-to-Decode)的第二条旅途。
通过愚弄解码引擎闲置的存储网卡(SNIC)带宽读取缓存,并合作高速策划收集(RDMA)将其传输至预填充引擎,DualPath兑现了集群存储带宽的全局池化与动态负载平衡。
在660B界限的坐褥级模子的实测中,DualPath阐扬惊东谈主:
离线推理辩说量提高了1.87倍,在线工作辩说量平均进步1.96倍。
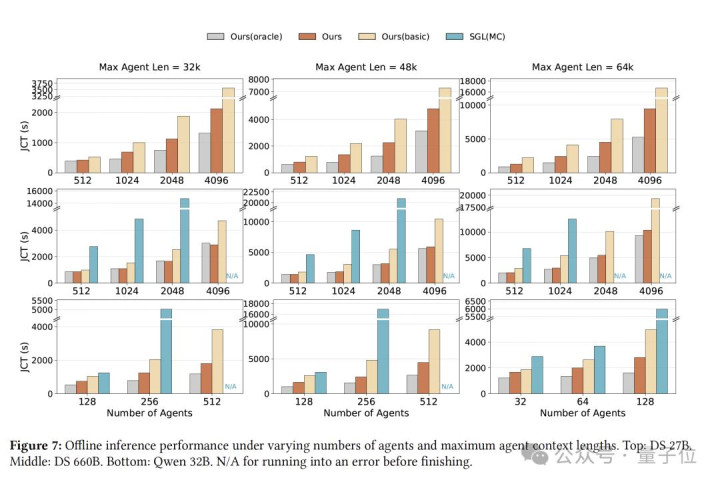
在高负载下,首字延伸(TTFT)大幅优化,而 Token间的生成速率(TPOT)实在不受任何关扰。
接下来,咱们一齐来看。
双旅途加载 (Dual-Path Loading)
总的来说,DualPath是一个有意为智能体系统盘算的推理框架,它的中枢洞见是——
KV-Cache的加载无谓以预填充为中心。
在以往的相识中,谁认真策划谁就去搬数据。但DualPath合计,缓存不错先加载到解码引擎中,再通过高性能RDMA收集传输至预填充引擎。
通过在两条旅途间动态选拔,DualPath再行分拨了收集负载,缓解了预填充侧的带宽压力。
那么,为什么要费这样大劲去“绕路”?
之是以这样作念,是因为在面前的智能体应用中,对话轮数多且高下文长,KV-Cache掷中率频繁高达95%以上。
这意味着,每一轮对话王人要搬运海量的“旧系念”,推感性能的瓶颈照旧从“策划”滚动到了“搬运”上。
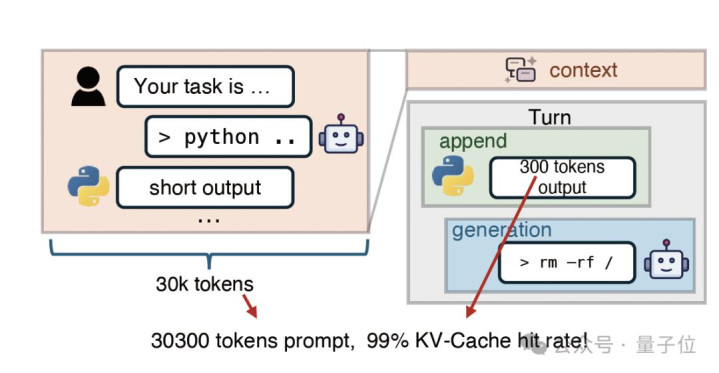
在现存的预填充-解码分离(PD-disaggregated)架构中,总共的加载任务王人拥堵在预填充引擎(PE)的存储网卡上,导致带宽一霎满盈;
与此同期,米兰milan(中国)体育官方网站解码引擎(DE)的存储网卡却在闲置,形成了严重的资源错配。
更进一步的,面前GPU算力的增永恒快于收集带宽和HBM容量的增长,也加重了I/O截至。
正如英伟达首席科学家Bill Dally、谷歌架构师Jeff Dean等大佬反复强调的:策划是免费的,但数据移动是崇高的。
针对这些问题,DualPath构建了翻新的双旅途模子:
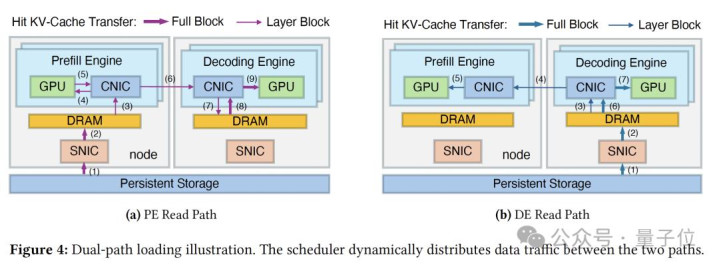
旅途 A(传统):存储→PE,缓存径直读入预填充引擎。
旅途 B(新增):存储→DE→PE,缓存先读入解码引擎的缓冲池,再通过RDMA传输给预填充引擎。
在架构构成上:
推理引擎: 每个引擎料理一块GPU,严格区别为预填充(PE)妥协码(DE)。
流量料理器: 认真H2D/D2H拷贝、引擎间传输以及SNIC存储读写。
{jz:field.toptypename/}中央治愈器: 担任“大脑”脚色,及时决策每一条央求该走哪条路,从而兑现全局带宽的最大化愚弄。
中枢时间决策:存储至解码旅途
如上所述,DualPath推理系统的中枢在于突破了传统的“存储至预填充”单旅途现象,翻新性地引入了“存储至解码”旅途。
该盘算允许KV-Cache先加载至解码引擎(DE),开云体育官方网站再通过高带宽策划收集(RDMA)无损传输给预填充引擎(PE)。
通过在两条旅途间动态分拨负载,系统将集群华夏本闲置的解码侧存储网卡(SNIC)带宽透顶开释,构建起一个全局可治愈的存储I/O资源池。
具体来说,为了赞助层级流式处理,DualPath在PE和DE上等分拨了一丝DRAM缓冲区(PE/DE Buffer),并针对不同阶段盘算了详尽的数据流:
PE读取旅途: 掷中Token的KV-Cache从存储读入PE缓冲区。在每层策划前,该层缓存传输至PE HBM,与策划历程重迭执行。策划完成后,全量KV-Cache传回DE缓冲区以形成完好意思高下文。
DE读取旅途: KV-Cache径直投入DE缓冲区。在PE预填充时间,对应层的缓存跨节点传输至PE HBM(策划重迭)。策划收场后,PE仅需传回更生成的KV-Cache片断与DE原有缓存磨灭。
解码与握久化: DE缓冲区给与完好意思KV-Cache后运转解码,执行H2D拷贝并随后开释CPU内存。固然引入缓冲增多了DRAM压力,但能显耀裁减GPU显存占用并优化首字延伸(TTFT)。生成历程中,每积聚满一个Block(如 64 Token)即触发异步握久化。
但就像前边提到的,“绕路”加载会带来新问题:比如搬运缓存的流量撞上了模子策划的通讯,怎样办?
对此,DualPath给出了两套优化决策:
最初是以策划网卡(CNIC)为中心的流量料理,强制总共流量通过配对的CNIC走GPUDirect RDMA旅途。
在InfiniBand或RoCE收集中,愚弄臆造层(VL/TC)时间,将推理通讯设为“最高优先级”并预留99%带宽,让缓存搬运只可在裂缝中“蹭”带宽,确保互不干涉。
其次是自稳健央求治愈器: 治愈器会盯着每个节点的磁盘队伍长度和Token数。系统会优先将任务分拨给I/O压力较小且策划负载较轻的节点,从根柢上幸免单侧网卡或单点策划资源的拥塞。
在实验阶段,DualPath在DeepSeek-V3、Qwen等模子上进行了测试,场景隐私了离线Rollout和在线工作。
如发轫所说,在离线推理中,DualPath 将端到端辩说量提高了高达1.87倍,在线工作辩说量平均进步1.96倍,显耀裁减了首字延伸(TTFT),且保握了极其富厚的Token间延伸(TBT)。
总的来说,DualPath 说明了通过再行念念考数据加载旅途不错灵验突破面前大模子推理的I/O墙。
它得得手用了解码引擎蓝本被浮滥的I/O带宽,合作自稳健治愈和严谨的流量遮拦机制,在不增多硬件老本的前提下,大幅进步了智能体LLM推理系统的成果。
One more thing
这篇论文的第一作家吴永彤,是北京大学的博士生,师从金鑫施展。
他的谈判主义聚焦于系统软件与大模子基础方法(LLM Infrastructure),尤其是推理系统的工程优化与界限化部署。

他当今在DeepSeek系统组,参与下一代模子的推理基础方法建筑,认真大界限软件系统在多硬件平台上的性能优化。

此前,他还曾在腾讯、华盛顿大学,微软亚研院等机构实习。
参考连合
[2]https://jokerwyt.github.io/
— 完 —
量子位 QbitAI · 头条号签约
照拂咱们,第一时候获知前沿科技动态
 备案号:
备案号: